代码评审(Code Review,以下简称CR)是指通过阅读代码来检查源代码与编码标准的符合性以及代码质量的活动。其目的是帮助提高代码质量,尽早发现由于编码习惯而造成的缺陷,重新梳理思路,最重要的是促进团队沟通共享,共同识别优秀的习惯和模式,把代码评审活动看做一种 学习活动而非批判活动。
内容
- 编码风格、文档与注释
- 代码结构
- 工具框架的使用
- 功能和业务逻辑、异常处理
- 安全性、性能
- 可测性
- 工具扫描出的违规项和编译器警告
好的软件除了满足功能需求之外,还应从长期维护的角度来考虑可读性、可扩展性等。没有明显问题,不代表明显没有问题。
然而,随着时间的推移,任何原本设计良好的代码都必然会逐渐腐坏,产生各种代码坏味道,变得难以理解,难以维护,缺陷频出。
随着代码质量下降,问题越来越多,程序员压力也越来越大,而士气也会受到影响,甚至原本的设计队伍都不在了。因而当需要修改bug或添加新需求时,人们更倾向于采用快速的打补丁方式来维护本已不堪的代码,致使代码质量进一步下降,从而造成更多的代码坏味道(Code Smell),形成恶性循环。
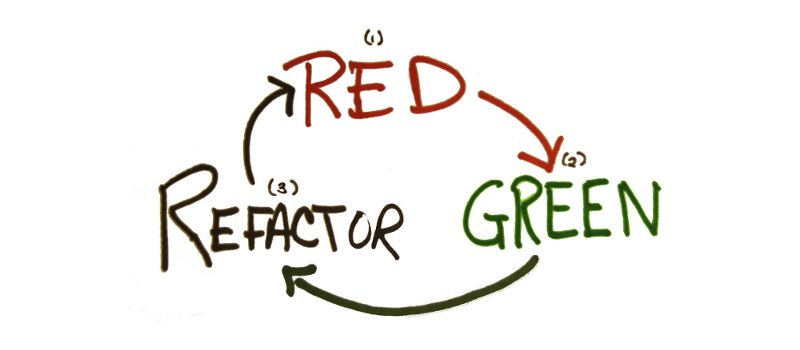
采用重构以后,可以有助于改善软件设计,使软件更加容易理解,发现潜在缺陷,从而使未来的编码更加快速。

重构是指在保持程序的全部功能的基础上重新组织代码结构,以更好地适应将来的变化。重构的类型有很多,如更改类名,改变方法名,或者提取代码到方法中。每一次重构,都要执行一系列的步骤,这些步骤要保证代码和原代码相一致。
全球敏捷之旅2015天津站现场视频。欢迎关注天津软件沙龙、天津谷歌开发者社区。感谢VTC视觉思维提供的现场图像记录。
感谢以下赞助商:优普丰Uperform、Odd-e之AHA大会、安迈无限Unlimax、清华大学出版社、图灵出版社、电子工业出版社、麦思博、天津i2社。
知名音乐网站Spotify的敏捷部落组织设计与工程文化近两年为人称道,其敏捷教练Henrik Kniberg发布的2段视频功不可没。为了让华人同胞能更好地理解视频的内容,我们成立了一个以Scrum方式工作的字幕翻译小组,将其翻译成中文。
视频简体中文字幕的创作是基于台湾志愿者创作的繁体中文版而成。感谢翻译Scrum团队:
PO 周龙鸿/翻译:王可帆, 任兰怡, 江岳龙, 余俊杰,
周玉萍, 林士智, 林清雅, 邱畯丞, 张峰睿, 张越程,
张钜鑫, 陈美凤, 黄久娟, 廖淑萍, Zephyr Hsu (西風)
简体中文版字幕贡献者:
关于这两段视频的解说,请看之前的两篇文章:
最近需要搭建一个Nexus私服,完全不能连接外网的那种,各种Jar包都是手动拷过来的,碰到需要gradle和maven强制重新下载依赖的问题。
第一次上传某个jar包(比如junit-4.12.jar)到Nexus上,然后调用gradle build可以正确下载到依赖包。但如果手动删掉了本地缓存的jar包(在~/.gradle下),这时从Nexus的下载过程中断,或者Nexus上暂时不存在这个jar包,那么即使Nexus恢复了正常下载,下次执行gradle build时就一直提示不能够找到jar包。
FAILURE: Build failed with an exception.
- What went wrong:
Could not resolve all dependencies for configuration ':testCompile'.
> Could not find junit:junit:4.12.
Searched in the following locations:
http://localhost:8081/nexus/content/groups/public/junit/junit/4.12/junit-4.12.pom
http://localhost:8081/nexus/content/groups/public/junit/junit/4.12/junit-4.12.jar
Required by:
org.codehaus.sonar:example-java-maven:1.0-SNAPSHOT
回到自己的工作目录下,带参数执行gradle强制刷新~/.gradle下的文件缓存
1 | gradle build --refresh-dependencies |
(本文改编自 @申导 翻译的《有效的单元测试》,如果对本文感兴趣,请支持正版书籍。)
编程是用计算机可理解的语言来表达你的想法和意图。对于Java程序员来说就是编写一种可以由Java编译器编译为可以运行在JVM上的字节码的代码。不止一种编程语言可以编写能运行在JVM上的代码,不过每种JVM语言都具有其独特的语法和感觉,但有一点是相同的:关于在JVM创建应用程序这件事上,她们都号称比Java更加简洁和更具表达力。
另类JVM语言的历史可追溯到15年前,那时Jim Hugunin在编写Jython,即一种JVM上的Python语言实现。尽管Jython难以获得发展的动力,但它启发了后来许多JVM语言的出现。
受到Jython的启发,2003年Groovy语言开始在JVM上登场,有着精简语法的Groovy承诺与Java代码之间流畅的互操作性和极高简洁性,使之成为JVM上编写脚本的重要选择。其他运行在JVM平台上的语言还包括Scala, JRuby, Clojure等,以及Java本身。
概括来说,各种另类JVM语言的一些潜在优势在于:
可迭代器(iterable),不仅限于list/str等,还包括任何包含有yield关键字的函数,后者未必有规律的迭代特征。标准库中的itertools包提供了更加灵活的产生迭代器的工具,这些工具的输入大都是已有的迭代器函数的封装,并且itertools给出的函数都是针对广义迭代器而言。而len()等函数是针对狭义迭代器,即sequence(i.e. str, list, tuple)而言的。
以内置函数range()为例,执行结果会是一次性计算好整个序列。这对于很长的序列来说会比较耗时,甚至带来性能问题。因而,python还提供了内置函数,提供了惰性求值版本,那就是xrange()。它利用yield特性,第一次执行时仅仅返回迭代器,不到用时是不会求值的。
实际上,itertools提供的函数都是惰性的,并且给原内置函数都重写了惰性版本。如imap()对于内置的map()。
扩展库Pipe则对内置函数和部分itertools进行了封装,提供了类似unix bash下的管道式调用风格,更接近人类从左到右的阅读习惯,使得代码更加优雅。其他动态语言,如ruby, c#-lambda java8-lambda也都提供了类似的链式调用形式。
另外,也提供了@Pipe装饰器,可以非常方便地扩展出自己的管道函数,或者继续封装其他itertools中的有用函数。
这里是Pipe官方给出的例子,用管道函数式编程解出https://projecteuler.net/中的三道题目:
1 |
|
注意:所有惰性求值的迭代器,都是只能求值一次的,如果再次求值会什么也得不到,因为yield堆栈已经走到底,无法回头。因此,当要对惰性迭代器重复使用时,必须故意地提前将其求值展开,或者利用itertools.tee来克隆一个迭代器。